Executable Onboarding: From Docs to Agents
May 20, 2026
Most backend services of any real size are painful to bring up locally, and once they are running, testing your changes by calling the actual APIs and walking through real flows is just as tedious. With the rise of LLMs, the better answer is not a longer README. It is a small agent. That agent can run the setup itself, remember what it has done, and follow instructions in plain English, both for bringing the service up and for driving the tests on top of it. This post is about one such agent, built for the service I work on day to day.
These days at work, I am mostly building on Frontier, an open source identity and billing platform from Raystack. On the identity side, it owns the org, project, and service-account model, and it manages roles and permissions through an authorization graph backed by SpiceDB. On the billing side, it tracks plans, subscriptions, features, usage, and invoices, and it integrates with a payment provider so the same organization model handles both “who can do what” and “who pays for what.” In practice, a B2B SaaS team using Frontier does not have to rebuild the usual primitives from scratch, like tenant isolation, role-based access, SSO, service accounts for API traffic, plans wired to feature entitlements, metered usage, and invoicing. All of those come out of the box, with one consistent org model underneath. That is what a mature platform here is supposed to do: take the parts every enterprise product re-implements and turn them into something the application team can configure rather than write.
That breadth is what makes Frontier useful, and it is also what makes it expensive to test locally. A single change can travel through identity, authz, and billing in the same request path. This post is about a Claude Code plugin I wrote to close that gap.
The Cost of a Real Local Test
Frontier needs PostgreSQL (two databases, its own and SpiceDB’s), a SpiceDB instance, migrations applied, and the server built from source against the right config. Once the server is running, you still have to authenticate, and there is more than one way to do it depending on who you are calling as: mail OTP for regular users, headers for service users, and a separate super-admin path tied to the config file. Each path gives you a different session, and each session can only call a specific subset of RPCs.
To test a change touching project role assignment end to end, you bring up the stack, run the OTP flow, capture the cookie, create an org, a project, a service user, and a few users with different roles, and only then can you call the RPC the change is actually about. On a good day, an hour is gone before you send the first meaningful request. On a bad day (a fresh laptop, a stale config, a SpiceDB version mismatch, a forgotten migration), it has been known to take a couple of days before someone gets the stack working end to end.
So most engineers do not do this. They write a unit test, watch CI go green, and ship. But a unit test does not catch the kinds of bugs a change like this usually causes: stale SpiceDB relations after a role update, a service user RPC that breaks on a missing header, a role assignment that reads correctly in code but leaves incomplete relations in the authz graph. These bugs are usually small once you find them. The painful part is that you only find them after the change has shipped.
The stakes are higher here than they are for most services. For an identity and billing platform, correctness and security are the whole point of the product. A small bug in authorization means someone sees data they should not see. A small bug in billing means a customer gets an invoice that is wrong. Neither of those is something you can fix quietly in the next release. They end up in incident channels and on support tickets. Catching this kind of bug locally, before it ships, is much cheaper than catching it after.
The Plugin
frontier-sandbox is a Claude Code plugin, published in a small marketplace repo. It does two things that are usually treated separately: it takes care of the local setup, and it drives the actual RPC testing on top.
Setup. One command brings up the stack: it detects an existing session and reuses it, otherwise it provisions PostgreSQL and SpiceDB (Docker by default, local install as a fallback), builds Frontier, runs migrations, and starts the server. rebuild restarts the binary without dropping data.
Testing. Authentication is where the plugin saves the most time. Frontier’s config already supports test identities with a hardcoded OTP (useful for local and CI, switched off in production), and the plugin knows how to take advantage of that. It works with a small, predictable set of users covering the three identity types you usually need: regular users, service users, and super admins. When you ask it to issue an RPC as one of them, it runs the OTP flow against that hardcoded value, persists the cookie, and reuses the session across subsequent calls. It also reads Frontier’s proto definitions, so it can resolve request and response shapes inline and emit a curl equivalent on demand.
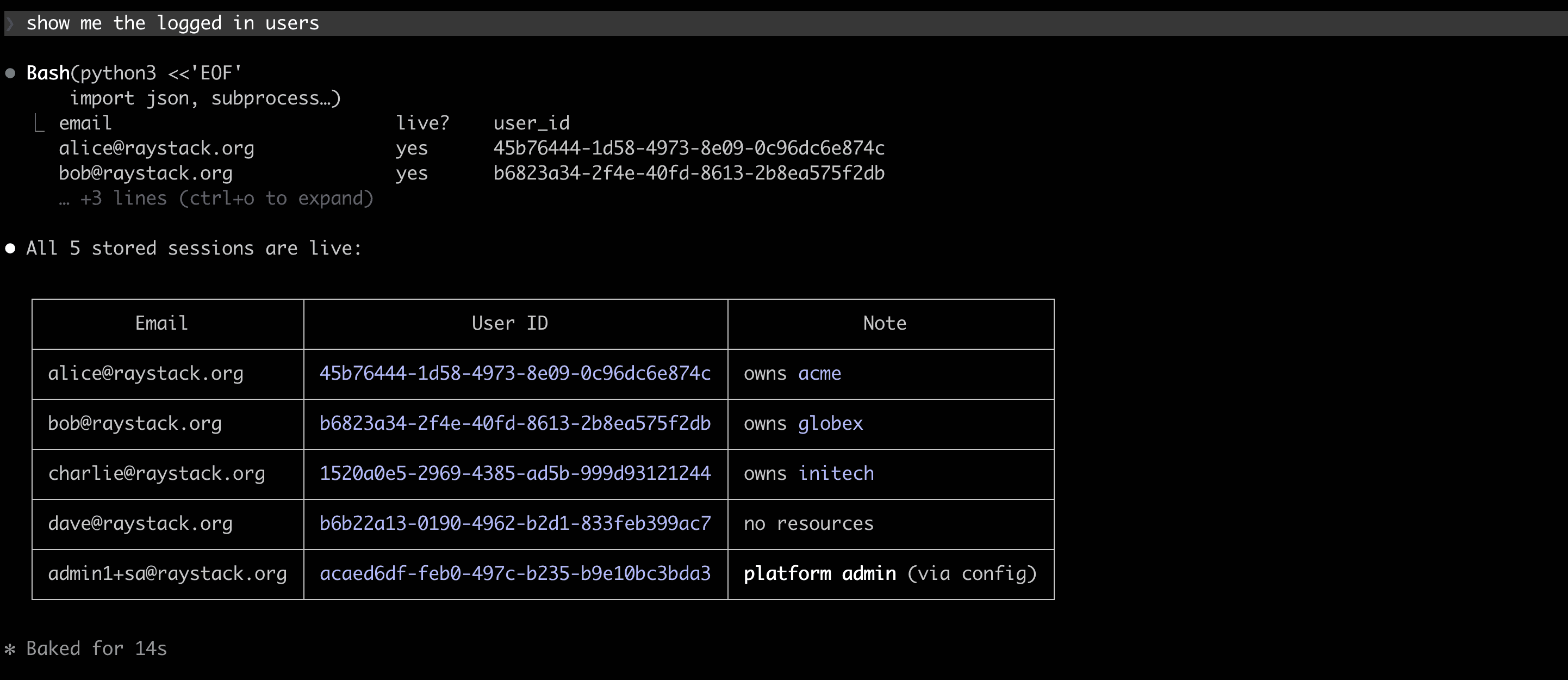
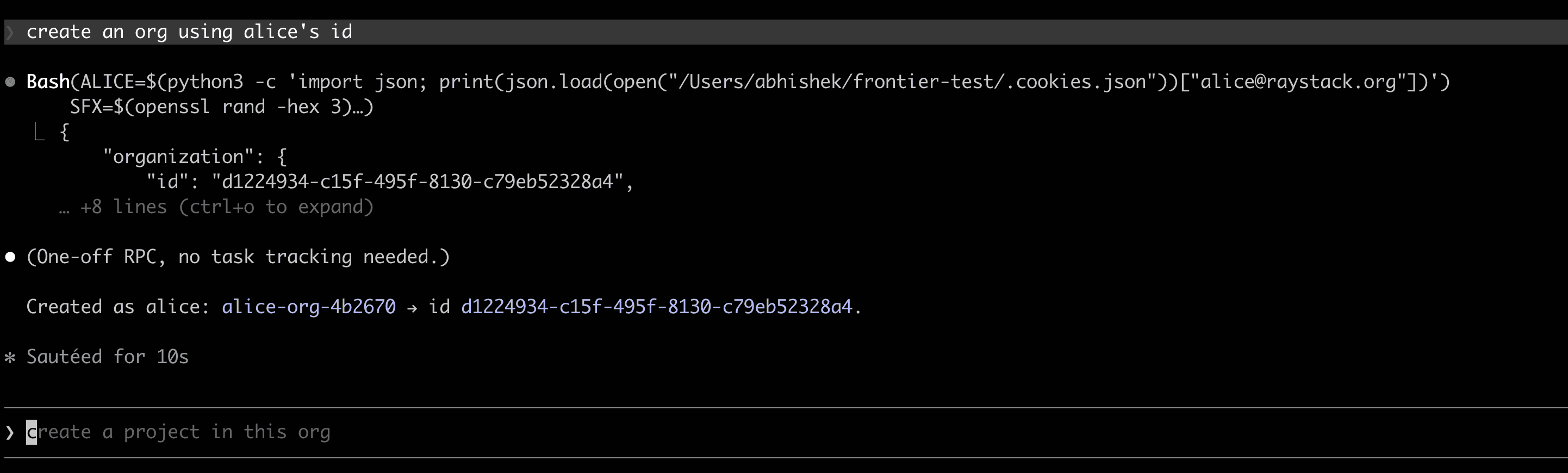
Beyond auth, the plugin takes care of the rest of the tedious testing work too. Without it, you would be hand-crafting curl calls or building Postman requests, filling in dummy payloads, looking up UUIDs you just created, reading JSON responses line by line, and then repeating the whole exercise for every edge case the API has, like invalid inputs, wrong-scope arguments, missing fields, and the occasional monkey test where you throw something deliberately strange at the endpoint to see how it reacts.
The plugin handles each of those: it shapes the request from the proto, fills in identifiers it already knows about, summarizes the response, and walks through the edge cases as it goes. You spend your time deciding what to test, not what to type.
Docker Gives State, the Plugin Gives Memory
You can get most of the way there with a docker-compose file and a seed script. That is in fact what the plugin uses for its Docker mode under the hood. What that setup does not give you is memory across a working session: which identity you logged in as, which cookie is still valid, which RPC needs the super-admin path, or which entities you just created and might want to call against next.
That continuity is the actual product here. You say “create an org as super admin,” then “now add user2 as a viewer on the project we just created,” and the skill figures out which project you mean, picks the identity with the right scope, and shapes the request accordingly. Docker compose can hand you a running service, but the plugin goes one step further: it hands you a running service that also keeps track of what you have already done with it in the same session.
What This Changed
A recent PR I shipped, #1481, touched project role assignment. Without the plugin, I would have run two or three scenarios by hand. With the plugin handling both the setup and the actual test calls, twenty-nine scenarios got covered before I opened the PR. I prompted and reviewed; the plugin did the running. The breakdown was nine on the happy path, seven on authorization (org owner, org admin without project role, project viewer who should be denied, unauthenticated caller, and the obvious adjacent cases), and thirteen on validation (invalid UUIDs, non-existent principals, wrong-scope roles, empty bodies). I posted the full table of what was tested and what passed as a comment on the PR, so the reviewer could see at a glance what had been covered without having to ask.
Each scenario ran against a clean database with the right identity, against a binary I had just rebuilt. The actual runs took seconds. The LLM proposed most of the cases itself, given the diff and the proto definitions. My job was to review the list, fix any issue that turned up during a run, ask the plugin to rebuild and restart the server, and retest. The bootstrap and the manual testing work that used to eat up that time are now effectively free.
The same run also caught a real bug. In earlier local testing, some of the authorization cases had been passing when they should have failed, because SpiceDB still had permission relations left over from previous runs. The code path doing the role update only ever added new relations and never cleaned up the old ones, so the leftover state was hiding the problem. Once every run started from a clean database, the false passes went away and I could finally tell whether the fix actually worked.
The Broader Lesson
Most backend services of any real size have a version of this problem. The people who built it know in their head how to bring it up locally, and the people who joined later usually do not. There are several ways to authenticate, all obvious to the original team and confusing to everyone else, and there are dozens of small decisions about which identity should issue which call. Newer engineers and people who only contribute now and then pay for that complexity on every change, and the README, if there is one, has usually drifted from how things actually work.
Turning the setup into something that actually runs the steps, rather than something that only describes them, works for a few simple reasons. It checks what is already installed instead of assuming. It can make sensible choices during setup, like which port to use or which dependency manager is available on the machine. It remembers what you have done in the current session, so the next step can build on it. And it lets you ask for things in plain language, instead of remembering exact flags and arguments. For a service where skipping end-to-end tests turns into production incidents, that is a small investment with a quick payoff.
Future Improvements
Seed data is fixed-shape today. The skill creates a small canned set of orgs, users, and projects. I would like to be able to describe the shape I need in plain English, something like “an org with twenty members, three projects, and a mix of viewer, editor, and owner roles”, and have the skill build it out, instead of writing each step by hand every time I need a new variation.
The interaction is too plain-text right now. When the skill needs an input from the user (Docker or local, which port to use, which user to log in as), it asks in regular chat text and waits for a typed reply. I would like those moments to show up as proper selectable choices inside Claude Code, the way Claude’s own prompts do, so the user can just pick an option instead of reading a paragraph and typing the answer back.
No browser-side testing yet. The current plugin understands Frontier’s proto layer and can call any RPC on demand, but Frontier also ships an Admin UI and a JavaScript SDK with a demo app. Anyone working on the JS SDK still has to test their changes by clicking through the UI by hand. I want to extend the plugin so it can drive the browser as well, simulating logins, button clicks, and form submissions, so SDK changes can be tested as easily as RPC changes already are.
If your service takes more than a few minutes to bring up locally, the highest-leverage version of this is probably the one you do not write a doc for. Instead, you write the executable equivalent of the doc and let your team invoke it. Your first version will be rough, but the time it saves your team is real, and you get that time back very quickly.
The plugin lives at whoAbhishekSah/claude-marketplace.